Guiding Yourself with Your Own Insights: Student-Driven Knowledge Distillation
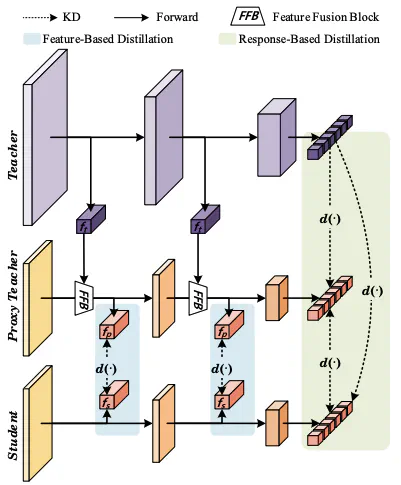 Overall architecture of the proposed SDKD method
Overall architecture of the proposed SDKD methodAbstract
Knowledge distillation (KD) stands as an efficient technique for compressing models, typically employing a teacher-student framework. Nevertheless, optimizing KD to yield models with reduced parameters and enhanced performance remains an area warranting deeper investigation. In this article, we recognize the significance of preserving structural consistency to enhance knowledge transfer efficiency between networks. Leveraging this insight, we introduce a novel approach termed Student-Driven Knowledge Distillation (SDKD), which integrates a proxy teacher intermediary between the primary teacher and student model. Specifically, we construct the architecture of the proxy teacher entirely based on the student network to generate logits that closely align with the distribution of the student network. Besides, we propose a Feature Fusion Block (FFB) to integrate features from the teacher network into the proxy teacher. FFB can not only provide high-quality feature-based knowledge for distillation but also impart response-based knowledge to facilitate the learning process. Extensive experiments illustrate that SDKD outperforms 29 state-of-the-art methods on several tasks, including image classification, semantic segmentation, and depth estimation.
Introduction
Deep Neural Networks (DNNs) have marked a significant breakthrough in machine learning, excelling in a wide range of tasks. However, the high complexity and huge amount of parameters inherent to DNNs present challenges for deployment in resource-limited devices, such as those used in edge-based multimedia applications. Despite the proliferation of such applications, performance limitations continue to be a major impediment in the field of multimedia research due to these constraints. In this article, we focus on knowledge distillation, a highly efficient and versatile technique that can be seamlessly adapted to various models and devices.
KD leverages the expertise of a larger and more accurate “teacher” network to boost the performance of a smaller “student” network, enhancing both effectiveness and efficiency. KD strategies can be categorized into offline distillation and online distillation. Studies have shown that online distillation methods outperform offline methods with the same teacher-student pairs due to the enhanced similarity from mutual training. This has led to the insight that a suitable teacher is more effective in guiding students than simply the best teacher. Consequently, recent research has focused on adaptive distillation methods that consider the correlation of similarities between teacher and student.
Building upon this observation, we propose a novel knowledge distillation approach, termed Student-Driven Knowledge Distillation (SDKD). Unlike conventional adaptive distillation methods that solely derive the proxy teacher from the teacher model, SDKD constructs the proxy teacher based on the architecture of the student model, thereby increasing the effectiveness of distillation (as depicted in the figure below).
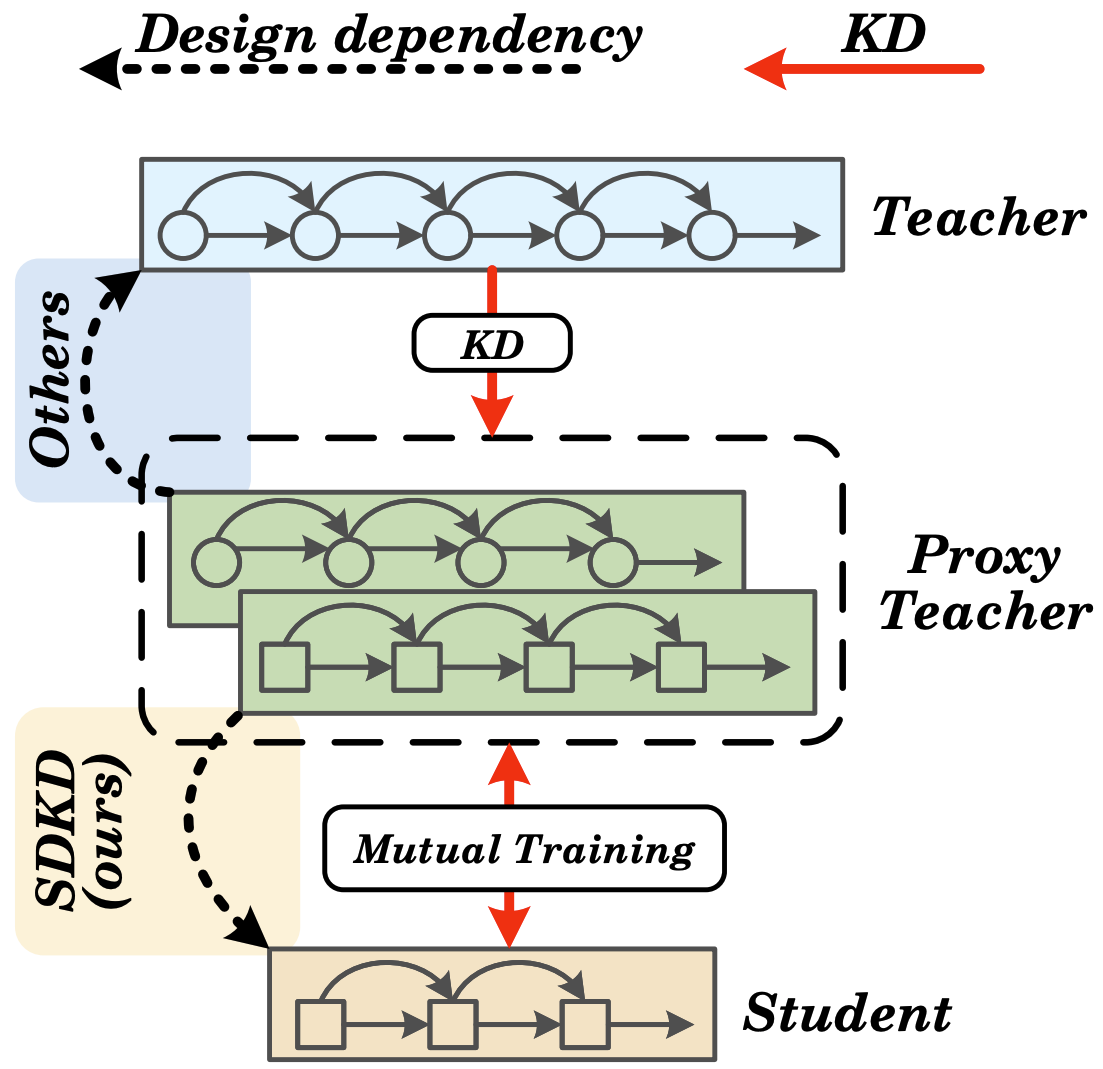
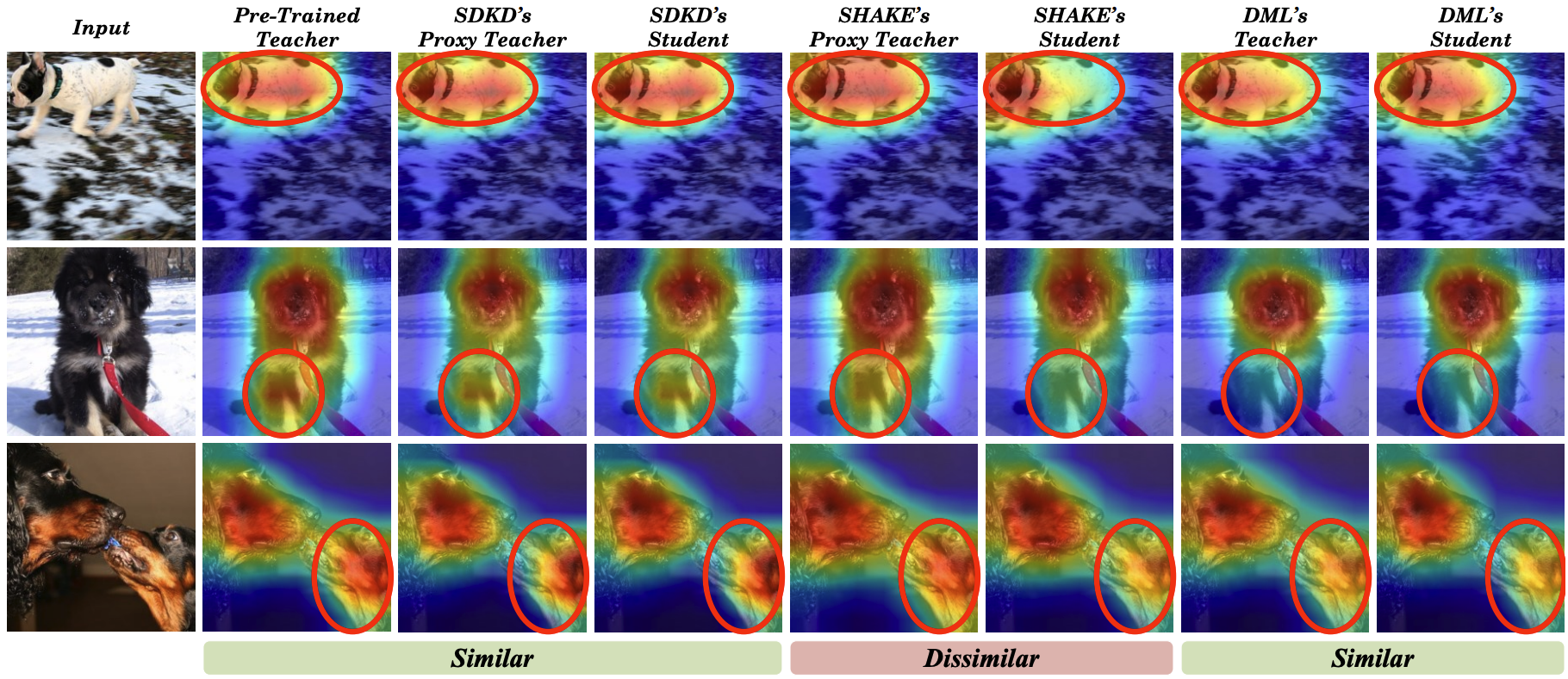
In SDKD, the proxy teacher is shaped according to the design of the student and trained using features from the teacher network, which facilitates the transfer of precise and assimilable knowledge to the student. Moreover, SDKD incorporates a Feature Fusion Block (FFB) to transfer features from the teacher to the proxy teacher and student, ensuring high compatibility with the student network. Furthermore, the weights of the student model are used to construct the proxy teacher, where only the FFB module needs to be additionally optimized, significantly reducing the overall training requirements. We employ the Grad-CAM++ to visualize the attention regions in networks during inference. Figure below shows a comparison of SDKD with the advanced adaptive distillation method SHAKE and online distillation method DML. SDKD exhibits a level of teacher-student similarity comparable to DML while significantly surpassing SHAKE. Furthermore, the proxy teacher in SDKD more closely resembles the pre-trained teacher, indicating that SDKD not only fully leverages the prior knowledge of the teacher but also effectively transfers it to the student.
Our contributions are summarized as follows:
We propose a novel knowledge distillation method, termed Student-Driven Knowledge Distillation, which addresses the disparity between teacher and student models by utilizing a specialized proxy teacher.
We introduce a new approach for designing the proxy teacher, whose architecture is identical to that of the student network. This enables the proxy teacher to provide logits that closely resemble the distribution of the student network, facilitating the learning process.
We design a Feature Fusion Block that enhances the capability of the proxy teacher by integrating features from the teacher network. It further improves the quality of feature-based and response-based knowledge.
We conducted extensive experiments on several benchmarks to validate the effectiveness of SDKD in both classification tasks and dense prediction tasks. SDKD demonstrates state-of-the-art performance across various datasets and architectures.
SDKD
The proposed SDKD introduces a novel framework that enhances knowledge transfer by leveraging structural similarity between teacher and student networks. Instead of deriving a proxy teacher from the teacher model, SDKD constructs the proxy teacher entirely based on the student’s architecture, minimizing structural discrepancies and facilitating smoother knowledge alignment.
1. Feature Fusion Block (FFB)
To enhance the proxy teacher’s capability, SDKD employs a Feature Fusion Block (FFB) that integrates intermediate features from the teacher and student networks. The FFB concatenates feature maps from both sources and refines them using sequential convolutional blocks, ensuring that the resulting fused features are dimensionally consistent with the student’s representations. This mechanism enables effective feature-based and response-based knowledge transfer.
2. Proxy Teacher Training
During training, the teacher and student parameters are frozen, and only the FFB is optimized. The proxy teacher is trained using a composite loss: $$ L_{PT} = L_{CE}(z_p, L) + L_{KL}(z_p, z_t) + L_{L1}(f_p, f_s) + \lambda L_{KL}(z_p, z_s) , $$ where $z_p, z_t, z_s$ denote the logits of the proxy teacher, teacher, and student respectively, and $f_p, f_s$ are their feature representations. This loss encourages the proxy teacher to absorb teacher knowledge while remaining closely aligned with the student network.
3. Student Optimization
Training is divided into two phases. In the first, the student learns directly from the teacher. In the second, both teacher and proxy teacher guide the student jointly. The student’s total loss is: $$ L_S = L_{CE}(z_s, L) + L_{KL}(z_s, z_t) + k[ L_{L1}(f_s, f_p) + L_{KL}(z_s, z_p) ] , $$ where $k$ is a binary mask that activates proxy-guided distillation after the initial phase.
4. Structural Similarity Perspective
SDKD is founded on the hypothesis that higher architectural similarity between teacher and student improves distillation performance. By designing the proxy teacher as a structural replica of the student, SDKD effectively reduces representational gaps and enhances the transfer of both feature- and response-level knowledge.