Efficient Implicit SDF and Color Reconstruction via Shared Feature Field
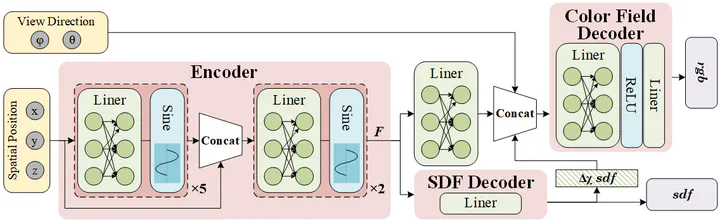 Overall architecture of the proposed SFF model
Overall architecture of the proposed SFF modelAbstract
Recent advancements in neural implicit 3D representations have enabled simultaneous surface reconstruction and novel view synthesis using only 2D RGB images. However, these methods often struggle with textureless and minimally visible areas. In this study, we introduce a simple yet effective encoder-decoder framework that encodes positional and viewpoint coordinates into a shared feature field (SFF). This feature field is then decoded into an implicit signed distance field (SDF) and a color field. By employing a weight-sharing encoder, we enhance the joint optimization of the SDF and color field, enabling better utilization of the limited information in the scene. Additionally, we incorporate a periodic sine function as an activation function, eliminating the need for a positional encoding layer and significantly reducing rippling artifacts on surfaces. Empirical results demonstrate that our method more effectively reconstructs textureless and minimally visible surfaces, synthesizes higher-quality novel views, and achieves superior multi-view reconstruction with fewer input images.
Introduction
3D scene reconstruction from multiple 2D images is a fundamental challenge in both computer graphics and computer vision. Recent advances in neural implicit representations have demonstrated significant potential in reconstructing appearance and geometry, as well as in synthesizing novel views. By leveraging rendering methods, frameworks that represent implicit surfaces through coordinate-based neural networks enable the conversion of 3D representations into 2D views. These frameworks are differentiable and rely solely on 2D images for ground truth.
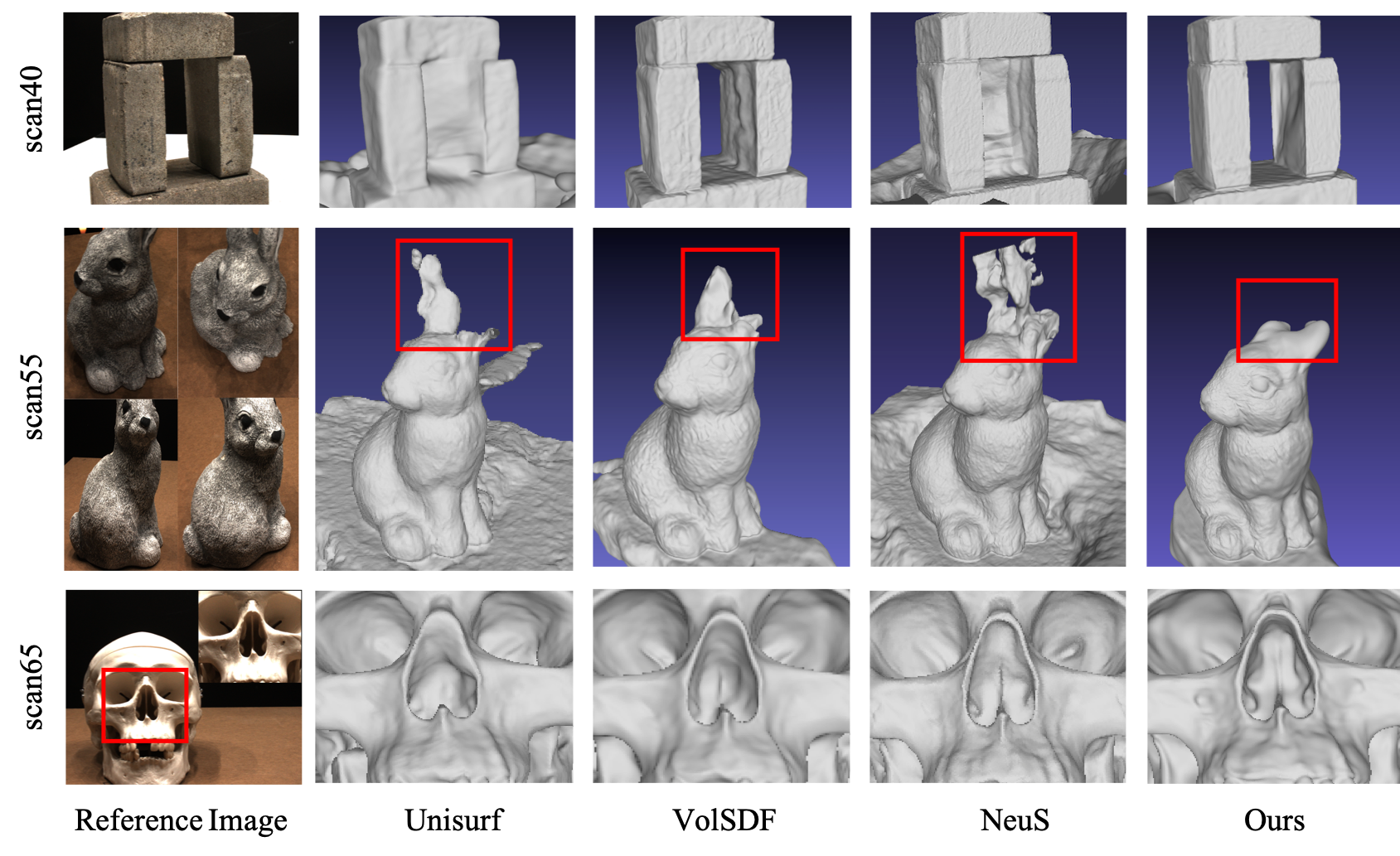
The effectiveness of reconstruction hinges on the choice of implicit representations, rendering techniques, density modeling, and the co-optimization of various fields. Recent studies have successfully combined signed distance fields (SDF) or occupancy fields with surface or volume rendering techniques, resulting in notably improved performance. These methods co-optimize different fields by either directly determining radiance on surfaces or by transforming learned implicit fields into local transparency functions for volume rendering, capturing both the geometry and appearance of solid and non-transparent 3D scenes with high fidelity. Moreover, Gaussian-Splatting employs anisotropic 3D Gaussian primitives to facilitate real-time reconstruction for a scene. Based on this, 2DGS adopts anisotropic 2D Gaussian primitives to streamline the extraction of surface information. However, challenges persist in accurately reconstructing textureless and rarely visible surfaces. As illustrated in the figure below, in scenes with complex topology or textureless regions that lack pixel-wise object masks for training supervision, these methods struggle to fully recover the scene.
In this paper, we introduce SFF to address challenges associated with textureless and rarely visible regions. The core concept is that different neural fields share a common feature from an encoder, which reduces ambiguity during the co-optimization of these fields by enriching each with supplementary information from others. Specifically, for each spatial position $(x, y, z)$ , only a single forward pass is needed. Unlike prior approaches that process the same spatial positions through different fields and link these fields with intermediate features, our method facilitates direct information sharing across fields. Each spatial position is encoded once and then decoded into the specific values of different fields using shallow decoders, some with as few as one linear layer.
Additionally, we observe that optimizing surface reconstruction often results in corrugated artifacts. Experiments indicate that these artifacts might be caused by high-frequency components introduced by positional encoding, which are ill-suited for this framework. To address this, we propose eliminating the positional encoding layer and using a periodic sine function as the activation in the encoder. This approach reduces corrugated artifacts and enhances surface smoothness.
In summary, our key contributions are:
We present an end-to-end Encoder-Decoder framework that conducts a single forward pass of spatial positions to encode diverse representations, which are then decoded into various fields. This approach enhances surface reconstruction and novel view synthesis for 3D scenes with complex topology, particularly in textureless and rarely visible regions.
We introduce a hybrid Sinus-ReLU activation function that supersedes the positional encoding layer, effectively diminishing mesh artifacts while preserving the quality of novel view synthesis.
Experimental results demonstrate that the proposed method more effectively utilizes the limited information available in a scene, achieving high-quality surface and appearance reconstruction.
Encoder-Decoder paradigm
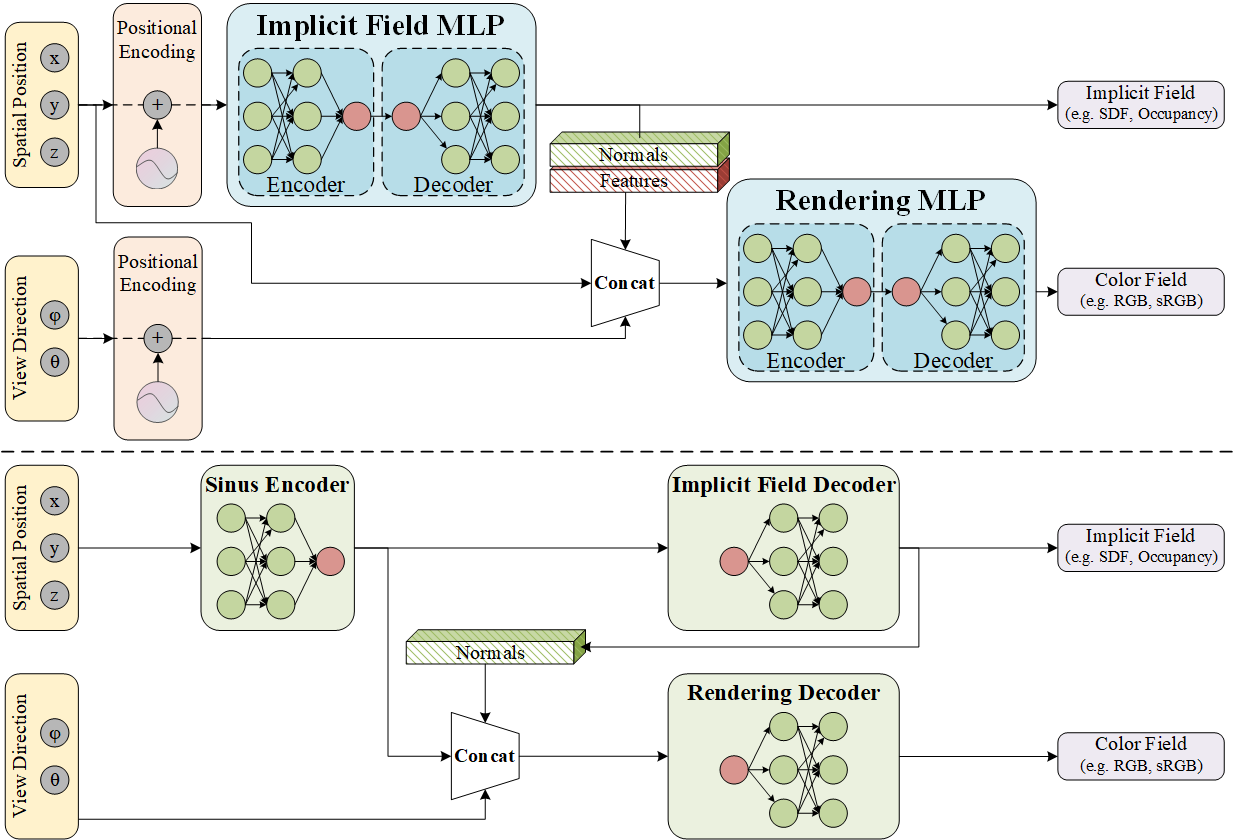
Our motivation arises from observing that each MLP in the common paradigm serves both as an encoder and a decoder. In this setup, both the SDF and the radiance field employ separate MLPs with positional encoding, leading to ambiguity in matching features to positions. While such models fit the training views well, they often struggle to accurately represent the underlying geometric structure.
To address this issue, we propose a new paradigm: a weight-shared encoder-decoder model. This model uses a single forward pass with spatial positions to obtain a general feature, which is then shared across multiple decoders. This approach provides greater regularization and reduces ambiguity in matching spatial positions to features across different forward passes.
Mixed Sinus-ReLU Activation Function Paradigm
Following NeRF, a positional encoding layer for capturing high-frequency geometry and texture is applied to the spatial positions and the viewing direction before they are fed into the encoder and the decoder. However, we empirically find that high-frequency positional encoding of the spatial position brings corrugated artifacts on the mesh, while low-frequency positional encoding results in relatively low-quality novel views.
To mitigate the corrugated artifacts and synthesize high-quality novel views, we remove the positional encoding layer and introduce a mixed Sinus-ReLU activation function paradigm for the encoder and decoders in our pipeline. Specifically, we use the sinus function as the activation function for the encoder, and ReLU for the decoders.
We follow SIREN to set the sinus function as:
$$ \text{Act}(\boldsymbol{x}) = \sin(\omega_0 \cdot \boldsymbol{x}) , $$ where $\omega_0$ is a trainable parameter, initially set to 3.
Experimental evidence indicates that position-dependent functions of densely sampled spatial points need higher-frequency variations. Sparse views, however, lack adequate supervision to model these functions, causing frequency-related artifacts. Our mixed Sinus-ReLU activation function paradigm allows the network to capture frequency information effectively, producing smooth meshes and high-quality novel views through the decoders.